
The Heroku platform is an absolutely fantastic way to have to not bother with devops within a small development company. We’ve been using it at interconnect for years now, and whilst it’s not entirely perfect, it takes away one set of headaches and does so at a reasonable cost.
All the services offer backups, and the VMs are built from scripts and are essentially read only. So if something catastrophic happened to one of our databases, we can roll back a day and be OK. Except… let me explain my fears around data.
Trust issues with providers
In our very earliest years we used a VPS provider that used Plesk. Everything was solid and stable until one day, we got a report that a site had been hacked. Then another. It turned out that a vulnerability had exposed our sites to being hacked. And they were. This resulted in a big old clean up operation and restoration from backups. Except the daily backups we’d been paying for turned out to be weekly. So the backups we had were three days old. Ever since then, I’ve preferred to have a way of pulling backups separately to a server under my own control, unless the provider is Kumina, because I know the people so well that I’m 100% certain they’re as paranoid as I am and they’ve never ever let me down. But in the era of hustle culture bros who move fast and break things, you need a safety net.
Creeping corruption
My next fear is corruption you don’t notice immediately. I can well imagine that if all the meta data for the posts on a site before a certain date got wiped out, most people wouldn’t notice for ages. Imagine you’ve got a site with 200,000 posts, and various elements of the first 100,00 were damaged – the long tail matters to these sites and suddenly it’s all gone. Well, thank heavens for backups!
Except, of course, most cloud providers don’t provider substantial generational backups. Instead, they keep a few days or a week or so. And that’s your lot. If you need to go back months you’d better hope a developer in the company left a dump on their laptop somewhere – except of course that very very few developers keep dumps of production systems on their laptops – it’s bad practice and only tends to happen in exceptional circumstances and should be deleted soon after use.
How we fix it today
In the end, I asked one of my Linux oriented colleagues, Gianluigi, to create a service that would connect to Heroku’s API and then download every database, and sync every S3 bucket. It worked, with some limitations. More recently, because he’d left but remains a good friend, he helped me with a crash course in Linux sysadmin basics and I was able to extend and improve some bits. The system is a service written in PHP that does all the work. I then asked another colleague internally, Jack, to extend things to cover the PostgreSQL databases we also now used and to create a dashboard so that I could monitor the backups easily without resorting to logging into the backups servers.
The dashboard also doesn’t run on the backups servers. I needed to keep the backups as safe as possible – they’d be a great honeypot for a hacker, so they’re onioned away, and the backups service isn’t reachable from outside. Instead, it messages the dashboard with information about the backups taken. The dashboard also provides details on application and framework versions, for security monitoring and making sure updates have been applied appropriately, and it also sends me a daily summary email showing me storage space available and what was backed up in the previous 24 hours.
Here are a few screenshots of the system, with some censoring, but I hope you catch how it works from what you see.
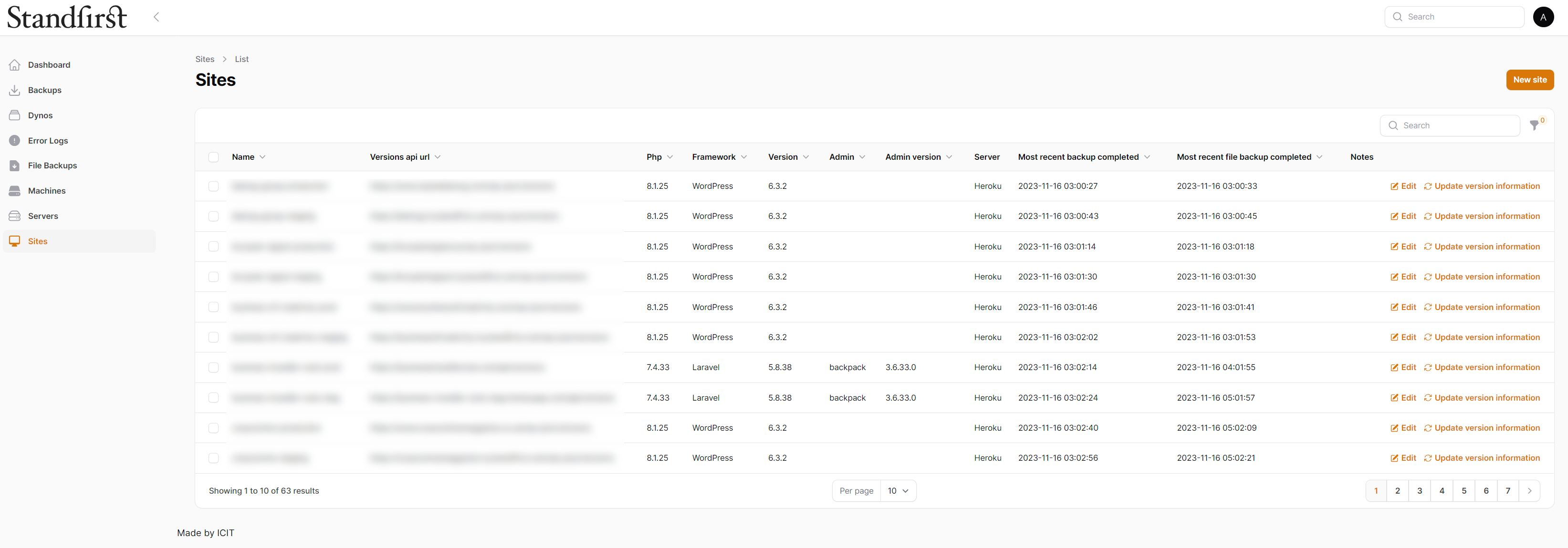


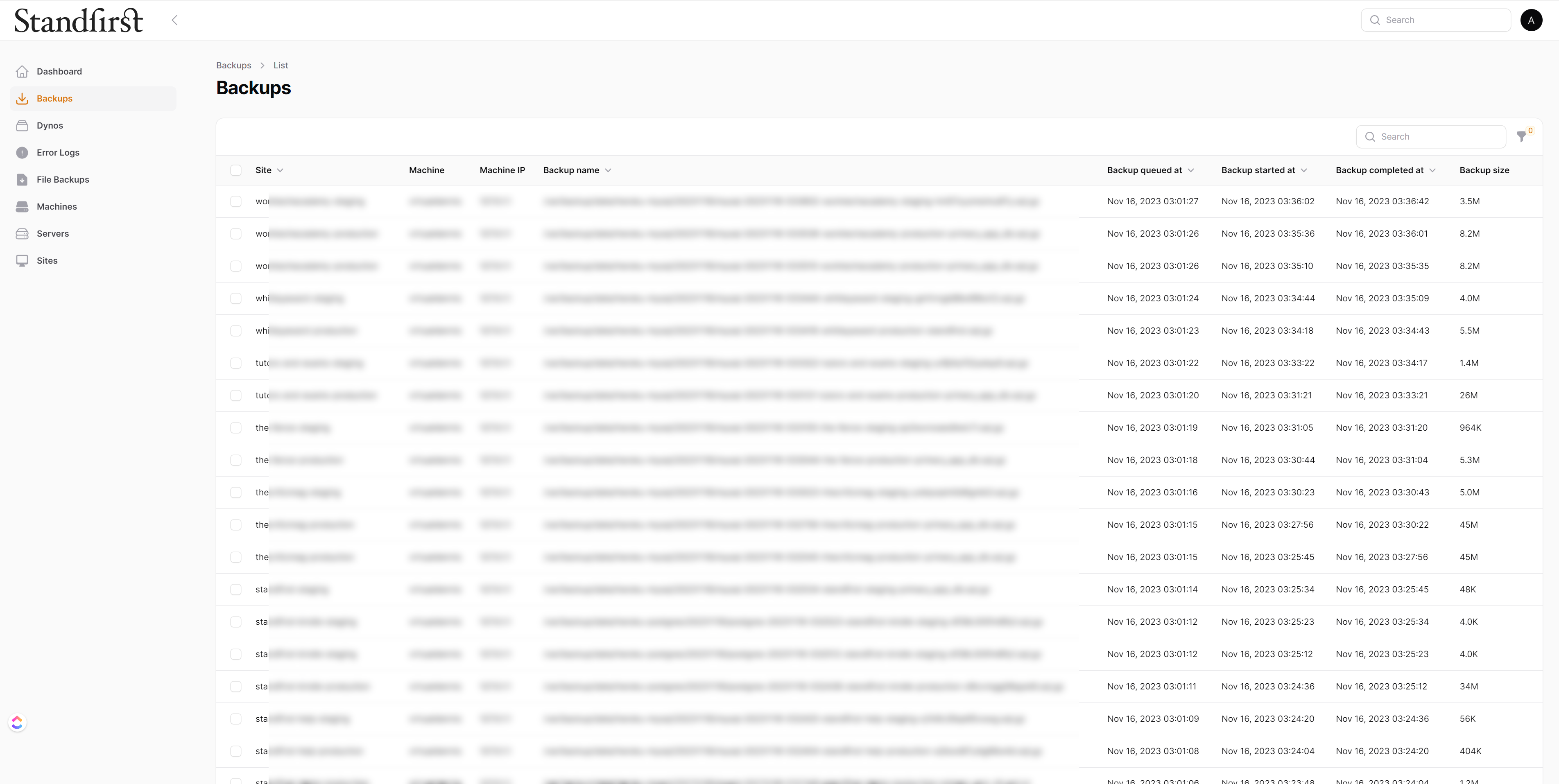
To commercialise, or not?
And now to one of the reasons why I’ve decided to write about this. In the past, I created the first version of Search Replace DB – a quick script and algorithm I knocked up to parse a database and search and replace items in it. A fast, dangerous tool that I released as free open source code. Other people took it and commercialised it into successful products. We didn’t. And with the code being integrated into wp-cli and most devs would use that in preference (myself included!), except in those tricky situations where command line access wasn’t possible – mostly on cheap hosts. I think we were right to release the code, but where we failed was in realising the commercial possibilities. And that’s left me a little torn.
So now I’m torn – it’s not easy to set up services in Linux, but once you do, these things just run and run. It’s also not going to be the easiest thing to work with, so I anticipate support costs being quite high. It’s proper server level work. And I certainly don’t feel inclined to build a SaaS that acts as a conduit for people’s backups. It’s just too risky to have a central pool of lots and lots of backups, and people find them lurking on S3 buckets all the time. So I want to put this out to the community. Is this something you’d find useful? Let us know in the comments below. If we did release it, the code would be open source, but access to the latest versions would be restricted.
I’m looking forward to hearing your thoughts!
Leave a Reply